https://atproto.com/guides/overview
2023-05-23 - made my first bot using the at proto API. 2023-08-10 - exploring max bittker’s custom feed (based off of why’s) https://github.com/MaxBittker/algoz but it’s all in go 😩😩😩
Questions that remain
- how does private data work? supposedly you could make this work by adding an e2e encryption layer so that all data is still public but you only store the encrypted data and upon consumption you have to decrypt everything
- what about semi-private data where you have a public view with private annotations? this should work the same as above where you just write a new lexicon for your private annotations, post them encrypted and have an unencrypted reference (or could be encrypted too?) back to the original piece of data you are referencing
- problem with this solution is how would querying continue to work? that’s one of the main benefits of at proto’s structure and you kind of lose all ability to meaningfully do that when you can only decrypt on the client… maybe something that zk-proofs can help with? Or something where you can run the queries and filters on the decrypted data but it only happens in an authorized indexer that can’t actually see your underlying data when it gets decrypted? i vaguely remember some paper or library that talks about the ability to do this (maybe shelter protocol was talking about this?)
- how do people make their own personal data repositories? are there plans to facilitate this? how is bluesky storing people’s data currently?
- what is the shape of the data? is there any specification on how other servers are supposed to store them?
- sounds like postgres from talking to daniel holmgren but supposedly you could persist this to whatever datastore you would want in the world of federation depending on the federation host?
- the SDK obfuscates a lot of the API… where/what is the actual web api?
- seems a bit strange that all access is done through the SDK rather than an open API
- can / will people be able to use bluesky as a place to host their data?
- will they charge access for this?
- how do you actually enable account portability?
(also known as Authenticated Transfer Protocol)
protocol developed by bluesky for large-scale distributed social applications
At a high level, the protocol encompasses
- “self-authenticating” data and identities which means that messages are all signed using the user’s keys. This also ensures data portability.
- designed for “twitter-scale” use cases (which is how they distinguish themselves from other decentralized social networks)
- this is what necessitates the BGS (indexers) for serving global data at scale. these are notably not intended for individuals to run but meant to make it possible for individuals to run their own PDS that make requests to BGS
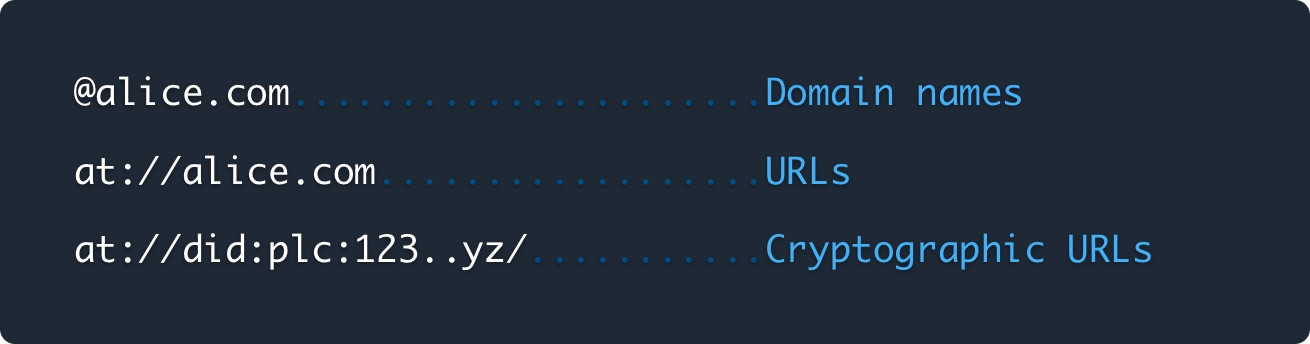
Identity
Users are identified via domain name (these also correspond to the user-visible handle), which map to a cryptographic URL (idid).
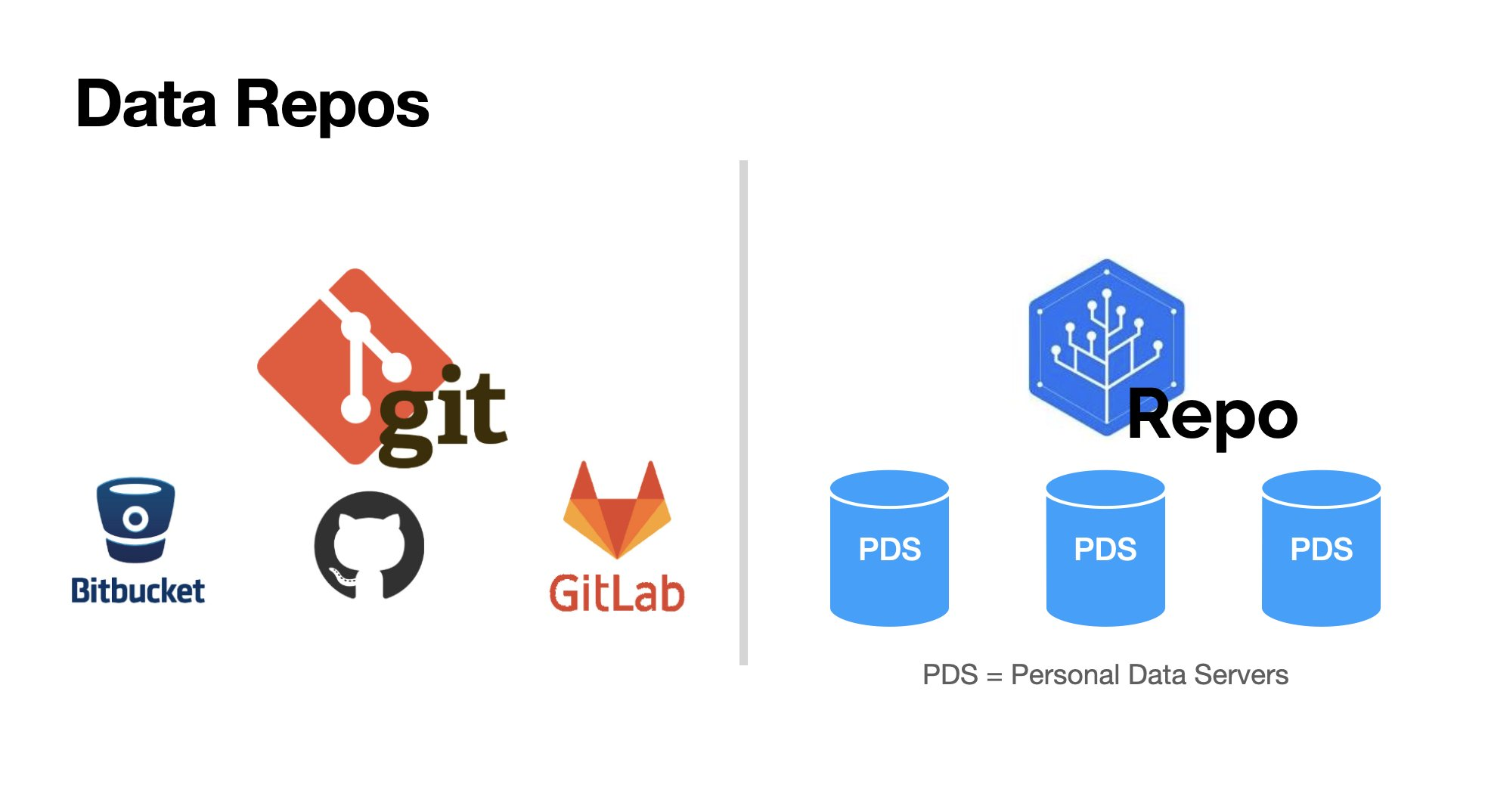
Data repositories
Data is exchanged in signed data repositories, which are collections of records signed by the authorizing user.
The data model uses IPLD1 as the representation and serializes to JSON and CBOR (a binary data serialization format)
Federation
Data repositories are synced in a federated fashion, using HTTPS + XRPC. XRPC
Schema
- AT proto data uses a ”lexicon” model to designate schema. (e.g.
app.bsky.feed.postorapp.bsky.feed.like) - Lexicon schemas are written in JSON, in a format similar to JSON-Schema
- schemas are identified using NSIDs (reverse-DNS), e.g.
com.atproto.repo.getRecord()orapp.bsky.feed.getPostThread() - schemas cannot change after it has been published (in a non backwards-compatible way). so changes require creating a new schema
Footnotes
-
IPLD refers to “any content addressable data with links to other content addressable data” based upon a JSON structure. In addition to the normal JSON data types, it includes “bytes” and “links” (content-addressable, hash-based links). It’s designed to support pathing and corresponding traversal over any data and is meant to define a common representation of basic types to accommodate more and more serial data formats in the future. One person describes it as “software for querying/traversing across any Merkle DAG” (source https://github.com/ipld/ipld/issues/39, https://ipld.io/docs/data-model/) ↩